Moving from PostgreSQL 9.0 to 9.2 under load
good day!
As you know, recently out of PostgreSQL 9.2 with a lot of interesting and useful things. Without thinking twice, we decided to upgrade our cluster streaming replication with 9.0 on 9.2. All would be nothing if not for several reasons:
the
Well, it's even more interesting... As we did and what happened read on.
What is all this?
the
This:
the
Difficulty:
the
What we found out?
A way to use Londiste from Skytools package-3.0, once we have moved with it from 8.4 to 9.0, so the experience is there. Replication with Londiste is convenient because that allows you to replicate individual tables and the database in the cluster (for example streaming replication replicates the entire cluster). Plus the last move we had streaming replication. And this is not a problem. Salitsilovaya data using Londiste will immediately be replicated to svezheotzhaty 9.2 slave using streaming replication. Great leaves pattern: replicaswatches on 9.2 we transparently complete data slave 9.2. So scheme and the algorithm:

1. Dminskaya part:
the
So technically everything is ready. It now remains to plan the replication progress and the time of switching. Day switch the selected Saturday. If something goes wrong, we still have Sunday. The event, we broke into two phases, a preparatory stage and the stage of switching. How to switch? For this we introduced two new DNS name for the new ligament 9.2: db-master and db-slave. At the right moment we will define these names in the config backend, and then restart the application.
Part of the activities of the preparatory plan already described above, but for completeness I will leave in a short form:
Until Friday:
the
Friday:
the
Saturday: is a day shift:
the
11.00-12.00 pause edit:
the
12.00-12.30 switch:
the
All. after this, replication using londiste becomes inconsistently, as all the external record (the source record clients on the website) went to the cluster, 9.2;
the
After switching:
the
After moving
the
Rollback. A plan in case something goes wrong:
the
Actually the whole algorithm. In the course of the event, of course, not everything went according to the master plan. Fortunately to resort to the fallback plan was not necessary.
If we talk about what went wrong, then there is only a couple of points,
the first point is a newly commissioned service and mechanism for manual transfer of circuits (which just should be avoided). A few words about the service: went the service is based on the work of the pgq was not quite clear how to replicate the schema pgq (pgq was himself part of the mechanism of replication). The manual transfer is also not corrected the situation, so I had to reinitialize the schema and restart the service (fortunately it's not critical, but still cant).
ERROR: insert or update on table violates foreign key constraint
DETAIL: Key is not present in table.
The conclusion is that transfer schemes better to do so:
Rename an existing empty schema in the destination database, then transfer all the schema from the source, from the database delete destination renamed the old scheme. Checking of the uniformity of the schemes can be done via the bash design. Run the command on both hosts, compare the output for compliance (use diff)
the
At the end of course we want to mention that need to check all the places where you may see an entry in the database and to exclude the possibility of recording when switching, when a part of the services/backend already switched to a new base, and the other part yet. If you think even further, theoretically it is possible certainly to translate volume to readonly, and to perform switching (mount/dmsetup/blockdev).
Well, a little bit of graphics.
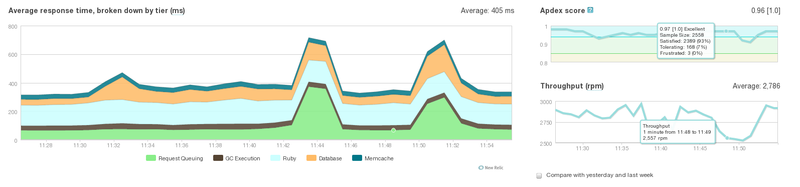
1. NewRelic. The process of switching backends.
2. Zabbix. The daily operation of the server with PG 9.0 (Monday September 10)

3. Zabbix. The daily operation of the server with PG 9.0 (Monday September 10)

4. Zabbix. The daily operation of the server with PG 9.2 + FlashCache (Monday September 17)

5. Zabbix. The daily operation of the server with PG 9.2 + FlashCache (Monday September 17)

The greatest evil in graphs Zabbix is a black line, reflecting the iowait. As can be seen, the use of flashcache will significantly reduce the load on the hard disks.
Who are interested in technical details:
how do I set up streaming replication in PostgreSQL, see here.
how is potulicka replication between clusters using PostgreSQL Skytools-3, see here.
That's the story of one Saturday. Thank you for your attention!
Article based on information from habrahabr.ru
As you know, recently out of PostgreSQL 9.2 with a lot of interesting and useful things. Without thinking twice, we decided to upgrade our cluster streaming replication with 9.0 on 9.2. All would be nothing if not for several reasons:
the
this is a production with a large daily attendance.
downtime is excluded.
Well, it's even more interesting... As we did and what happened read on.
What is all this?
the
-
the
- desire to get buns introduced in PostgreSQL 9.2; the
- transfer the PostgreSQL master to the server with flashcache.
This:
the
-
the
- hardware 3 servers, two of which hosted a bunch of master+slave 9.0 and another does the Unallocated server with flashcache; the
- bundle is replicated using the built-in streaming replicated; the
- with DB servers constantly, there are four backend with the app and the machine with Sphinx ohms.
Difficulty:
the
-
the
- cluster will not work if you just update the package with 9.0 on 9.2 (the cluster reinitialize or update); the
- pg_upgrade is not possible without stopping the cluster. the
- reinitialization and subsequent pg_restore also can not be done, because the downtime; the
- you cannot update master and then update the slave. Streaming replication between major versions will not work.
What we found out?
A way to use Londiste from Skytools package-3.0, once we have moved with it from 8.4 to 9.0, so the experience is there. Replication with Londiste is convenient because that allows you to replicate individual tables and the database in the cluster (for example streaming replication replicates the entire cluster). Plus the last move we had streaming replication. And this is not a problem. Salitsilovaya data using Londiste will immediately be replicated to svezheotzhaty 9.2 slave using streaming replication. Great leaves pattern: replicaswatches on 9.2 we transparently complete data slave 9.2. So scheme and the algorithm:
1. Dminskaya part:
the
-
the
- raise the master and slave 9.2. Slave 9.2 running on port 6543, since the standard port is already taken (see the picture); the
- raise between streaming replication; the
- install Skytools on sounstorm master 9.2; the
- configurable Londiste. The wizard 9.0 do provider of master 9.2 do the subscriber; the
- run the wizard 9.2 londiste and pgqd, then check the operation of the cords embedded in londiste means; the
- on the side of the provider is added to the replication of all tables and sequences(it is worth noting that capable of replication tables are only those, which are primary keys. If there are tables without keys, create keys there or have to move their hands... we were part of the schemes, which was cheaper to move by hand than to create the keys); the
- define those schemas and tables which will need to be moved by hands; the
- at the subscriber, run the replication test table and make sure that logs data provider 9.0 fall on the subscriber 9.2 and further on a streaming replication slave get to 9.2.
So technically everything is ready. It now remains to plan the replication progress and the time of switching. Day switch the selected Saturday. If something goes wrong, we still have Sunday. The event, we broke into two phases, a preparatory stage and the stage of switching. How to switch? For this we introduced two new DNS name for the new ligament 9.2: db-master and db-slave. At the right moment we will define these names in the config backend, and then restart the application.
Part of the activities of the preparatory plan already described above, but for completeness I will leave in a short form:
Until Friday:
the
-
the
- raise a new cluster of pg-9.2; the
- custom londiste between the pg-9.0 and pg-9.2; the
- raise a new slave.pg-9.2 on the nearby port and customizable streaming replication c master.pg-9.2; the
- to add provider in londiste all schemes which would not involve the creation of primary keys; the
- to check all the backend connectivity to new instances of PostgreSQL; the
- to double-check the configs for the new bases, limits of connections settings if so; the
- to configure the monitoring for the new database (we use zabbix, coupled with samopisnye bash-scripts jerking table pg_stat*); the
- to new bases to create dns names db-master and db-slave; the
- to prevent the editor on Saturday (this is just preduprejdenie leaders to be ready and not ask questions if anything).
Friday:
the
-
the
- disable night import (it's a hell of importing data, mechanism is that 100% breaks londiste-replication. This is internal kitchen of the project, but I mention it because any project can be the same component, so you should consider all elements that affect the surgery database); the
- start the data transfer via londistе. When you add a table to the subscriber, triggers replication through COPY, and then fixed consistent state of the table and it is considered to be replicated); the
- to prepare a list of schemes for manual transfer;
Saturday: is a day shift:
the
-
the
- check out the top 10 queries from the master and slave in 9.2 (maybe the game is just not worth it?); the
- to prepare the team for manual transfer of circuits (stupidly trying to console and at the right moment press Enter);
11.00-12.00 pause edit:
the
-
the
- to stop the crown, the demon of background tasks and wait for completion of active tasks; the
- to close the edit (at this point application it is impossible to perform write operations to the database, so we can avoid editing the database from the customer site, and the risk of inconsistently data at the time of restarting the application on the backend); the
- to move a dump the remaining schemas in the new database;
12.00-12.30 switch:
the
-
the
- fall apart londiste replication (print table, sequence, nodes, stop londiste and pgqd); the
- to correct the configs on the backend; the
- restart the application on the backend (nginx+passenger); the
- update config for sphinx and restart it;
All. after this, replication using londiste becomes inconsistently, as all the external record (the source record clients on the website) went to the cluster, 9.2;
the
-
the
- to correct a configuration of a demon of background tasks and run it. start of the crown; the
- to open the edit; the
- access to all controls, and to look for possible mistakes.
After switching:
the
-
the
- turn on the night import; the
- check the logs cron logs a demon of background tasks, lag replication.
After moving
the
-
the
- transfer the db-slave to the standard port for this:
- shut down the pg-9.0; the
- to configure a new pg-9.2 to work with full memory (unforgettable on host 2 PostgreSQL instance, so I had to divide between them the memory); the
- to run db-slave on port 5432, test connection with backend with Sphinx; the
- to verify the integrity and replication lag; the
- to put into operation the slave-side backend.
the backends running with the slave switch to the wizard; the
Rollback. A plan in case something goes wrong:
the
-
the
- to close the edit; the
- to stop the demon of background tasks and the crown, to wait for the completion of active tasks; the
- fix the configs the names of the database servers on the original, to restart the backends, run a daemon background task; the
- to roll back the configuration to sphinx; the
- open the edit.
Actually the whole algorithm. In the course of the event, of course, not everything went according to the master plan. Fortunately to resort to the fallback plan was not necessary.
If we talk about what went wrong, then there is only a couple of points,
the first point is a newly commissioned service and mechanism for manual transfer of circuits (which just should be avoided). A few words about the service: went the service is based on the work of the pgq was not quite clear how to replicate the schema pgq (pgq was himself part of the mechanism of replication). The manual transfer is also not corrected the situation, so I had to reinitialize the schema and restart the service (fortunately it's not critical, but still cant).
ERROR: insert or update on table violates foreign key constraint
DETAIL: Key is not present in table.
The conclusion is that transfer schemes better to do so:
Rename an existing empty schema in the destination database, then transfer all the schema from the source, from the database delete destination renamed the old scheme. Checking of the uniformity of the schemes can be done via the bash design. Run the command on both hosts, compare the output for compliance (use diff)
the
# for i in schema_1 schema_2 schema_3; do psql -ltAF. -U postgres -c "\dt $i." db_name |cut-d. -f1,2 ; done |while read line ; do echo "$line" - $(psql -qAtX -U postgres -c "select count() from $line" db_name); done
At the end of course we want to mention that need to check all the places where you may see an entry in the database and to exclude the possibility of recording when switching, when a part of the services/backend already switched to a new base, and the other part yet. If you think even further, theoretically it is possible certainly to translate volume to readonly, and to perform switching (mount/dmsetup/blockdev).
Well, a little bit of graphics.
1. NewRelic. The process of switching backends.
2. Zabbix. The daily operation of the server with PG 9.0 (Monday September 10)
3. Zabbix. The daily operation of the server with PG 9.0 (Monday September 10)
4. Zabbix. The daily operation of the server with PG 9.2 + FlashCache (Monday September 17)
5. Zabbix. The daily operation of the server with PG 9.2 + FlashCache (Monday September 17)
The greatest evil in graphs Zabbix is a black line, reflecting the iowait. As can be seen, the use of flashcache will significantly reduce the load on the hard disks.
Who are interested in technical details:
how do I set up streaming replication in PostgreSQL, see here.
how is potulicka replication between clusters using PostgreSQL Skytools-3, see here.
That's the story of one Saturday. Thank you for your attention!



Комментарии
Отправить комментарий