The use of Lisp in production
Grammarly the heart of our business — Central language features — written in Common Lisp. Now the engine handles more than a thousand sentences per second, massturbate horizontally and reliably serves us in production for almost 3 years.
We have noticed that there are almost no posts about the deployment of Lisp software in a modern cloud infrastructure, so we decided to share our experiences is a good idea. Runtime and programming environment of Lisp provides several unique, a bit unusual, capabilities to support production systems (for the impatient — they are described in the last part).

Contrary to popular opinion, Lisp is incredibly practical for production systems. Just put, around us, many Lisp systems: when you are looking for air ticket on Hipmunk or riding the subway in London, used a Lisp program.
Our Lisp-conceptual services represent a classic AI app that operates on a huge pile of knowledge created by linguists and researchers. Its main used resource is the CPU, and this is one of the largest consumers of computing resources in our network.
The system works on a normal Linux images deployed in AWS. We use SBCL production and CCL on most development machines. One of the enjoyable moments when using Lisp, you have the choice of several developed implementations with different pros and cons: in our case, we optimized the speed on the server and the compilation speed when developing (why is it critical for us is described later).

At Grammarly, we use a variety of programming languages for the development of our services: in addition to languages for the JVM and JavaScript and we also write in Erlang, Python and Go. Needs encapsulation of services allows us to use the language or the platform that is best suited for the task. This approach has a cost in maintenance, but we appreciate the choice and freedom more than rules and templates.
We also try to rely on simple, not tied to languages, infrastructure and utilities. This approach frees us from many problems in the integration of all this zoo of technologies in our platform. For example, statsd is a great example of an incredibly simple and useful service that is very easy to use. Another Graylog2, it provides a chic specification for logging, and despite the fact that there was ready libraries to work with it from CL, it was very easy to assemble from what's available in Lisp ecosystem. Here is all the code you need (and almost all of it just word for word translation of the specification):
the
Lack of libraries in the ecosystem is one of the most frequent claims to Lisp. As you can see, 5 libraries used in this example, for such things as coding, compression, getting a Unix time, and the socket connection.
Lisp libraries do exist, but, as in all integrations, libraries, we are faced with problems. For example, to connect Jenkins CI, we had to use xUnit and it was not very easy to find specifications for it. Fortunately, helped a question on Stackoverflow in the end we built it in your own library test should-test.
Another example — using HDF5 for the exchange of machine learning models: we spent some time to adapt the low-level library hdf5-cffi for our reality, but we had to spend a lot more time to update our AMI (Amazon Machine Image) to support the current version of the C library.
Another principle that we follow in the platform Grammarly is the maximum decomposition of different services to ensure horizontal scalability and functional independence about it the post of my colleague. Thus we do not need to interact with databases in critical parts of our services linguistic kernel. However, we use MySQL, Postgres, Redis and Mongo for the backend store, and we have successfully used CLSQL, postmodern, cl-redis and cl-mongo to access them from Lisp.
We use Quicklisp to manage external dependencies and simple system of packaging source code library with the project for their own libraries and forks. The Quicklisp repository contains more than 1000 Lisp libraries: not a super huge number, but quite sufficient to meet all the needs of our productions.
For deployment in production we are using generic stack: the application is tested and going through Jenkins, is delivered to the server by Rundeck and runs there through Upstart as a normal Unix process.
In General, the problems that we face when integrating Lisp applications in the cloud world is not radically different from those which we meet in many other technologies. If you want to use a Lisp in production and experience the pleasure of writing Lisp code, there is no real technical reason not to do this!

No matter how perfect the story is not all about rainbows and unicorns.
We have created an esoteric (even by the standards of the Lisp world) and in the process ran into some limitations of the platform. One such surprise was the exhaustion of memory at compile time. We rely heavily on macros, and some of them are disclosed in thousands of lines of low level code. It turned out that the SBCL compiler implements many optimizations, allowing us to enjoy a fairly fast generated code, but some of them require exponential time and memory. Unfortunately, there is no way to turn off or adjust them. Despite this, there is a known General solution, style call-with-* that allows you to sacrifice a little efficiency for a better modularity (which proved decisive in our case) and otlivami.
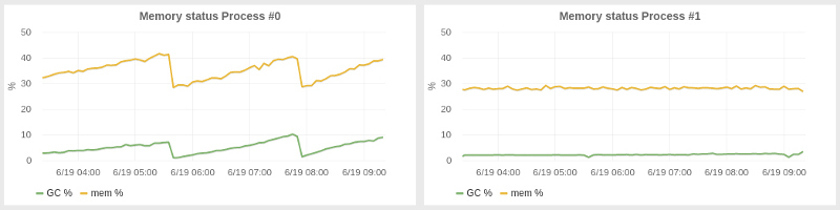
Adjusting the garbage collector to reduce delays and improve resource utilization in our system was less unexpected problem in contrast to the taming of the compiler. SBCL provides a suitable garbage collector based on generations, although not as sophisticated as in the JVM. We had to customize the generation sizes and found that the best option was to use a heap larger: our application consumes 2-4 gigabytes of memory, but we launched it on a bunch of 25G, which automatically led to the increase in the size of the first generation. Another setting that we had to do far less obvious, was the software running the GC every N minutes. With a larger lot, we noticed a gradual increase in memory usage over periods of tens of minutes, due to which more time was spent on GC and decreased application performance. Our approach with periodic GC the system has resulted in a more stable state with nearly constant memory consumption. On the left is the system without our settings, and right — effect of periodic GC.
From all these difficulties, the most unpleasant bug that I've ever met was a network bug. As usually happens in such situations, the bug was not in the app, and underlying platform (this time — SBCL). And, moreover, I ran it twice to two different services, but the first time I couldn't figure it out, so I had to work around it.
When we started the launch of our service to essential loads in production, after some time of normal functioning of all the servers suddenly started to slow down and eventually become unavailable. After a lengthy investigation of suspected input data, we found that the problem was in the race in low-level network code, SBCL, specifically in the way the function call socket — getprotobyname, which was not thread-safe. It was a very unlikely race, so that she showed herself only in highly loaded network service when this function is called tens of thousands of times. It knocked one worker thread after another, gradually introducing the system to anyone.
Here is the fix, at which we stopped, unfortunately, it cannot be used in a broader context. (The bug was sent to the team and SBCL have been fixed, but we still use this hack, just in case :)
the

System Common Lisp implement many of the ideas of the legendary Lisp machines. One of the most outstanding is an interactive environment SLIME. While the industry awaits maturation LightTable and similar tools, Lisp programmers quietly enjoying such opportunities in SLIME for many years. Behold the power of the to the teeth armed and operational battle station in action.
But SLIME it's not just the Lisp approach to the IDE. Being a client-server application, it allows you to run your backend on a remote machine and connect to it from within your local Emacs (or Vim, if you have no choice, with SLIMV). Java programmers can think about JConsole, but then you are constrained by a predefined set of operations and can produce any introspection or change what you want. We would not be able to catch the race in the functions of the socket without these features.
Moreover, the remote console is not the only useful utility provided by SLIME. Like many IDE it can go into the source code of the functions, but unlike Java or Python on my machine is the source code of SBCL, so I often view the source codes of the implementation, it helps me a lot in learning what is happening "under the hood". For the case with socket bug this was also an important part of the debugging process.
Finally, another super useful tool for introspection and debugging, we use — TRACE. She completely changed my approach to debugging programs, now instead of the tedious code to run through the steps I can perform the whole picture. This tool also helped us to localize our bug with sockets.
With trace, you specify the function to trace, run the code, and Lisp prints all calls to this function and its arguments and the results that it returns. This is something similar to the trace stack, but you don't need a full stack and you dynamically get a stream of traces, without stopping the application. trace is a print on steroids that allows you to quickly penetrate into the inside code of any complexity and to track complex execution paths of the implementation programme. Its only drawback — it is impossible trasit macros.
Here's a snippet of the trace I did just today, to make sure that a JSON request to one of our services is formed correctly and returns the desired result:
the
So, to debug our awful socket bug I had to dig deep in the network code SBCL and examine the called function, then you can connect SLIME to the dying server and try trasit these functions one after the other. And when I received the call that never came back — that was it. In the end, after clarifying in the manual that the function is not thread safe and meeting several mentions about it in the comments the source code of SBCL, I was convinced his hypothesis.
This article is about the fact that Lisp proved to be surprisingly robust platform for one of our most critical projects. It is consistent with the General requirements of modern cloud infrastructure, and despite the fact that this stack is not very widely known and popular, it has its strengths — you just need to learn how to use them. What can we say about the power of the Lisp approach to the solution of complex problems, for which we love him so much. But that's another story.
Approx. the interpreter:
I am doubly glad about the use of Common Lisp in production, writing and even written by people from the CIS, after all, we practice working with this stack are almost there. I hope after reading this article, someone will pay attention to this much underrated technology.
Article based on information from habrahabr.ru
We have noticed that there are almost no posts about the deployment of Lisp software in a modern cloud infrastructure, so we decided to share our experiences is a good idea. Runtime and programming environment of Lisp provides several unique, a bit unusual, capabilities to support production systems (for the impatient — they are described in the last part).
Wut Lisp?!!
Contrary to popular opinion, Lisp is incredibly practical for production systems. Just put, around us, many Lisp systems: when you are looking for air ticket on Hipmunk or riding the subway in London, used a Lisp program.
Our Lisp-conceptual services represent a classic AI app that operates on a huge pile of knowledge created by linguists and researchers. Its main used resource is the CPU, and this is one of the largest consumers of computing resources in our network.
The system works on a normal Linux images deployed in AWS. We use SBCL production and CCL on most development machines. One of the enjoyable moments when using Lisp, you have the choice of several developed implementations with different pros and cons: in our case, we optimized the speed on the server and the compilation speed when developing (why is it critical for us is described later).
A stranger in a strange land
At Grammarly, we use a variety of programming languages for the development of our services: in addition to languages for the JVM and JavaScript and we also write in Erlang, Python and Go. Needs encapsulation of services allows us to use the language or the platform that is best suited for the task. This approach has a cost in maintenance, but we appreciate the choice and freedom more than rules and templates.
We also try to rely on simple, not tied to languages, infrastructure and utilities. This approach frees us from many problems in the integration of all this zoo of technologies in our platform. For example, statsd is a great example of an incredibly simple and useful service that is very easy to use. Another Graylog2, it provides a chic specification for logging, and despite the fact that there was ready libraries to work with it from CL, it was very easy to assemble from what's available in Lisp ecosystem. Here is all the code you need (and almost all of it just word for word translation of the specification):
the
(defun graylog (message &key level backtrace file line-no)
(let ((msg (salza2:compress-data
(babel:string-to-octets
(json:encode-json-to-string #{
:version "1.0"
:facility "lisp"
:host *hostname*
:|short_message| message
:|full_message| backtrace
:timestamp (local-time:timestamp-to-unix (local-time:now))
:level level
:file file
:line line-no
})
:encoding :utf-8)
'salza2:zlib-compressor)))
(usocket:socket-send (usocket:socket-connect
*graylog-host* *graylog-port*
:protocol :datagram :element-type '(unsigned-byte 8))
msg (length msg))))
Lack of libraries in the ecosystem is one of the most frequent claims to Lisp. As you can see, 5 libraries used in this example, for such things as coding, compression, getting a Unix time, and the socket connection.
Lisp libraries do exist, but, as in all integrations, libraries, we are faced with problems. For example, to connect Jenkins CI, we had to use xUnit and it was not very easy to find specifications for it. Fortunately, helped a question on Stackoverflow in the end we built it in your own library test should-test.
Another example — using HDF5 for the exchange of machine learning models: we spent some time to adapt the low-level library hdf5-cffi for our reality, but we had to spend a lot more time to update our AMI (Amazon Machine Image) to support the current version of the C library.
Another principle that we follow in the platform Grammarly is the maximum decomposition of different services to ensure horizontal scalability and functional independence about it the post of my colleague. Thus we do not need to interact with databases in critical parts of our services linguistic kernel. However, we use MySQL, Postgres, Redis and Mongo for the backend store, and we have successfully used CLSQL, postmodern, cl-redis and cl-mongo to access them from Lisp.
We use Quicklisp to manage external dependencies and simple system of packaging source code library with the project for their own libraries and forks. The Quicklisp repository contains more than 1000 Lisp libraries: not a super huge number, but quite sufficient to meet all the needs of our productions.
For deployment in production we are using generic stack: the application is tested and going through Jenkins, is delivered to the server by Rundeck and runs there through Upstart as a normal Unix process.
In General, the problems that we face when integrating Lisp applications in the cloud world is not radically different from those which we meet in many other technologies. If you want to use a Lisp in production and experience the pleasure of writing Lisp code, there is no real technical reason not to do this!
The hardest bug I've ever are debugged
No matter how perfect the story is not all about rainbows and unicorns.
We have created an esoteric (even by the standards of the Lisp world) and in the process ran into some limitations of the platform. One such surprise was the exhaustion of memory at compile time. We rely heavily on macros, and some of them are disclosed in thousands of lines of low level code. It turned out that the SBCL compiler implements many optimizations, allowing us to enjoy a fairly fast generated code, but some of them require exponential time and memory. Unfortunately, there is no way to turn off or adjust them. Despite this, there is a known General solution, style call-with-* that allows you to sacrifice a little efficiency for a better modularity (which proved decisive in our case) and otlivami.
Adjusting the garbage collector to reduce delays and improve resource utilization in our system was less unexpected problem in contrast to the taming of the compiler. SBCL provides a suitable garbage collector based on generations, although not as sophisticated as in the JVM. We had to customize the generation sizes and found that the best option was to use a heap larger: our application consumes 2-4 gigabytes of memory, but we launched it on a bunch of 25G, which automatically led to the increase in the size of the first generation. Another setting that we had to do far less obvious, was the software running the GC every N minutes. With a larger lot, we noticed a gradual increase in memory usage over periods of tens of minutes, due to which more time was spent on GC and decreased application performance. Our approach with periodic GC the system has resulted in a more stable state with nearly constant memory consumption. On the left is the system without our settings, and right — effect of periodic GC.
From all these difficulties, the most unpleasant bug that I've ever met was a network bug. As usually happens in such situations, the bug was not in the app, and underlying platform (this time — SBCL). And, moreover, I ran it twice to two different services, but the first time I couldn't figure it out, so I had to work around it.
When we started the launch of our service to essential loads in production, after some time of normal functioning of all the servers suddenly started to slow down and eventually become unavailable. After a lengthy investigation of suspected input data, we found that the problem was in the race in low-level network code, SBCL, specifically in the way the function call socket — getprotobyname, which was not thread-safe. It was a very unlikely race, so that she showed herself only in highly loaded network service when this function is called tens of thousands of times. It knocked one worker thread after another, gradually introducing the system to anyone.
Here is the fix, at which we stopped, unfortunately, it cannot be used in a broader context. (The bug was sent to the team and SBCL have been fixed, but we still use this hack, just in case :)
the
#+unix
(defun sb-bsd-sockets:get-protocol-by-name (name)
(case (mkeyw name)
(tcp 6)
(:udp, 17)))
Back to the future
System Common Lisp implement many of the ideas of the legendary Lisp machines. One of the most outstanding is an interactive environment SLIME. While the industry awaits maturation LightTable and similar tools, Lisp programmers quietly enjoying such opportunities in SLIME for many years. Behold the power of the to the teeth armed and operational battle station in action.
But SLIME it's not just the Lisp approach to the IDE. Being a client-server application, it allows you to run your backend on a remote machine and connect to it from within your local Emacs (or Vim, if you have no choice, with SLIMV). Java programmers can think about JConsole, but then you are constrained by a predefined set of operations and can produce any introspection or change what you want. We would not be able to catch the race in the functions of the socket without these features.
Moreover, the remote console is not the only useful utility provided by SLIME. Like many IDE it can go into the source code of the functions, but unlike Java or Python on my machine is the source code of SBCL, so I often view the source codes of the implementation, it helps me a lot in learning what is happening "under the hood". For the case with socket bug this was also an important part of the debugging process.
Finally, another super useful tool for introspection and debugging, we use — TRACE. She completely changed my approach to debugging programs, now instead of the tedious code to run through the steps I can perform the whole picture. This tool also helped us to localize our bug with sockets.
With trace, you specify the function to trace, run the code, and Lisp prints all calls to this function and its arguments and the results that it returns. This is something similar to the trace stack, but you don't need a full stack and you dynamically get a stream of traces, without stopping the application. trace is a print on steroids that allows you to quickly penetrate into the inside code of any complexity and to track complex execution paths of the implementation programme. Its only drawback — it is impossible trasit macros.
Here's a snippet of the trace I did just today, to make sure that a JSON request to one of our services is formed correctly and returns the desired result:
the
0: (GET-DEPS
("you think that's bad, hehe, i remember once i had an old 100MHZ dell unit i was using as a server in my room"))
1: (JSON:ENCODE-JSON-TO-STRING
#<HASH-TABLE :TEST EQL :COUNT 2 {1037DD9383}>)
2: (JSON:ENCODE-JSON-TO-STRING "action")
2: JSON:ENCODE-JSON-TO-STRING returned "\"action\""
2: (JSON:ENCODE-JSON-TO-STRING "sentences")
2: JSON:ENCODE-JSON-TO-STRING returned "\"sentences\""
1: JSON:ENCODE-JSON-TO-STRING returned
"{\"action\":\"deps\",\"sentences\":[\"you think that's bad, hehe, i remember once i had an old 100MHZ dell unit i was using as a server in my room\"]}"
0: GET-DEPS returned
((("nsubj" 1 0) ("ccomp" 9 1) ("nsubj" 3 2) ("ccomp" 1 3) ("acomp" 3 4)
("punct" 9 5) ("intj" 9 6) ("punct" 9 7) ("nsubj" 9 8) ("root" -1 9)
("advmod" 9 10) ("nsubj" 12 11) ("ccomp" 9 12) ("det" 17 13)
("amod" 17 14) ("nn" 16 15) ("nn" 17 16) ("notice" 12 of 17)
("nsubj" 20 18) (aux 20 19) ("rcmod" 17 20) ("prep" 20 21)
("det" 23 22) ("pobj" 21 23) ("prep" 23 24)
("poss" 26 25) ("pobj" 24 26)))
((<0,3 you> <4,9 think> <that 10,14> <'s 14,16> <bad 17,20> <, 20,21>
<hehe 22,26> <, 26,27> <i 28,29> <remember 30,38> <once 39,43>
<i 44,45> <46,49 had> <an 50,52> <old 53,56> <100MHZ 57,63>
<dell 64,68> <unit 69,73> <i 74,75> <was 76,79> <a using to 80.85>
<as 86,88> <a 89,90> <server 91,97> <98,100 in> <my 101,103>
<room 104,108>))
So, to debug our awful socket bug I had to dig deep in the network code SBCL and examine the called function, then you can connect SLIME to the dying server and try trasit these functions one after the other. And when I received the call that never came back — that was it. In the end, after clarifying in the manual that the function is not thread safe and meeting several mentions about it in the comments the source code of SBCL, I was convinced his hypothesis.
This article is about the fact that Lisp proved to be surprisingly robust platform for one of our most critical projects. It is consistent with the General requirements of modern cloud infrastructure, and despite the fact that this stack is not very widely known and popular, it has its strengths — you just need to learn how to use them. What can we say about the power of the Lisp approach to the solution of complex problems, for which we love him so much. But that's another story.
Approx. the interpreter:
I am doubly glad about the use of Common Lisp in production, writing and even written by people from the CIS, after all, we practice working with this stack are almost there. I hope after reading this article, someone will pay attention to this much underrated technology.



Комментарии
Отправить комментарий