Memo Evangelist PostgreSQL: Replicants vs replication

Continuing the series of publications "Bulletin of the Evangelist PostgreSQL..." (1, 2) dear editors again contacted, this time with the promised review of the mechanisms of replication in PostgreSQL and MySQL. The main reason for writing was frequent criticism of MySQL replication. As is often the case, the typical criticism is a heady mixture of truth, half-truths and evangelism. All this is much replicated different people without much attempt to understand heard. And since this is a pretty broad topic, I decided to put the analysis in a separate publication.
So, in cultural exchange and in anticipation of the HighLoad++, where a will probably be as usual a lot of criticism of MySQL, consider the replication mechanisms. First, some boring basic things for those who haven't.
the
Types of replication
Replication is logical and physical. Physical is a description of the changes at the file level data (simplified: write these bytes at this offset on this page). Logical describes the changes at a higher level without reference to a specific representation of the data on the disk, there may be options. You can describe the changes in terms of the rows of tables, for example the operator
UPDATE can be specified as a sequence of pairs (old value, new value) for each changed row. In MySQL this type is called row-based replication. And you can just record the text of all SQL queries that modify data. This type in MySQL is called statement-based replication.Physical replication is often called a binary (especially in the PostgreSQL community) that is incorrect. Data format both logical and physical replication can be text (that is chelovekami) and binary (requiring processing to be read by a person). In practice, all formats in the MySQL and PostgreSQL binary. It is obvious that in the case of statement-based replication in MySQL text queries can be read "the naked eye", but all official information will still be in binary form. Therefore, the log used in replication, is binary regardless of the format of replication.
the
and logical replication:
the
independence from storage format of data: master and slave can have different data representation on the disk of different processor architecture, different table structure (subject to compatibility of patterns) with different configurations and the location of the data files of different storage engines (MySQL), different versions of servers, and indeed the master and slave can be different DBMS (and the following solutions for "cross-platform" replication exist). These properties are used often, especially in large-scale projects. For example, in rolling schema upgrade.
read: with each node in replication, you can read the data without any restrictions. With physical replication is not easy (see below)
multi-source: merging changes from different masters to one slave. Usage example: aggregating data from multiple shards to build statistics and reports. The same as Wikipedia uses multi-source for these purposes
multi-master: with any topology, you can have more than one available on the server entry if necessary
partial replication: option to replicate only a single table or schema
compactness: the amount of data moved over the network less. In some cases, much less.
the
features of physical replication:
the
easier configuration and use: by Itself, the problem byte mirroring one server to another, much simpler logical replication, with its many scenarios and topologies. Hence the famous "set it and forget it" in all halevanah "MySQL vs PostgreSQL".
the requirement for 100% identity of the nodes: physical replication is possible only between identical servers, down to the architecture of the processor paths to the tablespace files, etc This can often be a problem for large-scale cluster replication, because changes in these factors causes a complete shutdown of the cluster.
no records on the slave: follows from the previous paragraph. Even a temporary table cannot be created.
read from the slave is problematic: reading from the slave is possible, but not without problems. Cm. "Physical replication in PostgreSQL" below
the limitations of the topology: no multi-source and multi-master possible. In the best case of cascading replication.
no fractional replication: is derived from the same requirements for 100% identity of data files
large overhead: need to transfer all changes to the data files (index operation, vacuum and other internal accounting Department). So network load is higher than with logical replication. But as usual depends on the number/type of indexes, load, and other factors.
And the replication can be synchronous, asynchronous, and semisynchronous regardless of format. But this fact has little to do with things discussed here, so it is leave out.
the
Physical replication in MySQL
It itself is not, at least built into the server itself. There are architectural reasons, but this does not mean that it is impossible in principle. Oracle could relatively little effort to implement physical replication for InnoDB, and this is would cover the needs of most users. A more sophisticated approach would require the creation of some API, realizing that alternative engines could support physical replication, but I don't think it will ever happen.
But in some cases, physical replication can be implemented by external means, for example, using the DRBD or hardware solutions. The pros and cons of this approach discussed repeatedly and in detail.
In the context of comparison with PostgreSQL it should be noted that the use of DRBD and similar solutions for physical MySQL replication is most likely warm standby in PostgreSQL. But the amount of data moved over the network in the DRBD will be higher because DRBD operates on block device level, which means not only replicated entries in the REDO log (transaction log), but the entry in the data files and update the meta information of the file system.
the
Logical replication in MySQL
This topic causes the most unrest. Moreover, much of the criticism is based on the report "Asynchronous MySQL replication without censorship or why PostgreSQL will conquer the world" Oleg Tsarev zabivator and accompanying articles on habré.
 I wouldn't emphasize one particular report, if I hadn't referred to it in approximately one out of every ten comments to the previous article. So you have to answer, but I would like to emphasize that the ideal of the reports does not happen (I personally get bad reports), and all the criticism is directed not at the speaker, as for the technical inaccuracies in the report. I would be glad if it will help to improve future versions.
I wouldn't emphasize one particular report, if I hadn't referred to it in approximately one out of every ten comments to the previous article. So you have to answer, but I would like to emphasize that the ideal of the reports does not happen (I personally get bad reports), and all the criticism is directed not at the speaker, as for the technical inaccuracies in the report. I would be glad if it will help to improve future versions.Overall, the report pretty much technically inaccurate or just incorrect statements, some of them I addressed in the first part of the memo Evangelist. But I don't want to drown in the details, so I will understand the main points.
So, in MySQL logical replication is represented by two subtypes: statement-based and row-based.
Statement-based is the most naive way to organize replication ("let's just pass to slave SQL command!"), that's why she appeared in MySQL first and it was a very long time. It even works as long as SQL commands strictly deterministic, i.e. lead to the same changes regardless of the time of execution, context, triggers, etc. written About it tons of articles, I will not here dwell.
In my opinion, statement-based replication is a hack and "legacy" in the style of MyISAM. Surely someone somewhere else finds a use for it, but avoid this.
 Interestingly, on the use statement-based replication, says in his report Oleg. The reason is row-based replication would generate hundreds of terabytes of data per day. In General it is logical, but how does this fit with the statement "PostgreSQL conquer the world", if PostgreSQL asynchronous statement-based replication at all? That is, PostgreSQL would generate terabytes of updates a day, "a bottleneck" is to be expected would be the disk or the network and the conquest of the world would have to wait.
Interestingly, on the use statement-based replication, says in his report Oleg. The reason is row-based replication would generate hundreds of terabytes of data per day. In General it is logical, but how does this fit with the statement "PostgreSQL conquer the world", if PostgreSQL asynchronous statement-based replication at all? That is, PostgreSQL would generate terabytes of updates a day, "a bottleneck" is to be expected would be the disk or the network and the conquest of the world would have to wait. Oleg notes that logical replication is usually CPU-bound, that is, depends on the CPU, and the physical — usually I/O bound, that is, depends on the network/disk. I'm not quite sure in this assertion: CPU-bound workload with one hand transformed into an elegant I/O bound once the active data set ceases to fit in memory (a typical situation for the same Facebook, for example). And with it leveled, and a large part of the difference between logical and physical replication. But in General I agree: logical replication requires relatively more resources (and this is its main weakness), and less physical (and this is almost its only advantage).
The reasons to inhibit the replication can be many: it not only odnopotochnitsa or lack of CPU, it could be network, disk, inefficient queries, inadequate configuration. The main damage from the report is that he is "rowing one size fits all", explaining all the problems some "architectural error MySQL" and leaving the impression that the solution of these problems. That's why he was happily adopted by the evangelists, all kinds. In fact, I believe that 1) most of the problems has a solution and 2) all these problems also exist in the implementations of the logical replication for PostgreSQL, perhaps even in a more severe form (see "Logical replication for PostgreSQL").
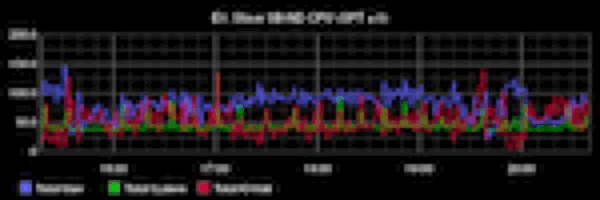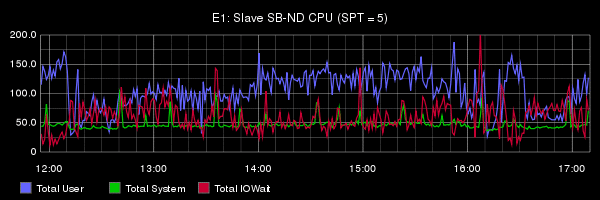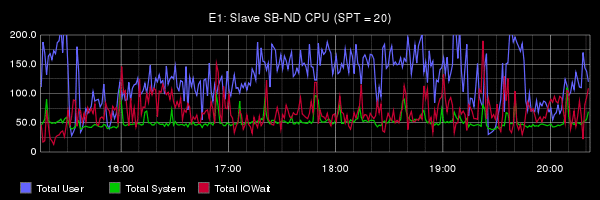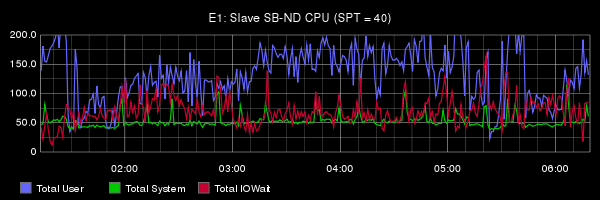 From the report of Oleg is very difficult to understand what actually was the problem in his tests: there is no analysis, there is no metric, nor on the OS level or at the server level. For comparison: publikacja engineers Booking.com on the same theme, but with detailed analysis and without "Evangelical" conclusions. I especially recommend to see Under the Hood. So the right thing to do and show benchmarks. In the report of Oleg's benchmarks have 3 slide.
From the report of Oleg is very difficult to understand what actually was the problem in his tests: there is no analysis, there is no metric, nor on the OS level or at the server level. For comparison: publikacja engineers Booking.com on the same theme, but with detailed analysis and without "Evangelical" conclusions. I especially recommend to see Under the Hood. So the right thing to do and show benchmarks. In the report of Oleg's benchmarks have 3 slide.I will just briefly list the possible problems and solutions. I foresee a lot of comments along the lines of "and the elephant, everything works fine and no voodoo!". Answer them once and not anymore: physical replication is easier to set up than logic, but its capacity is not enough for everyone. Logical more opportunities, but there are drawbacks. Here we describe ways of minimizing the disadvantages for MySQL.
the
If you hit a disk
Often emit weak slave of the machine for reasons of "well, it's not the main server will go down and this old basin". In the old basin is usually a weak disk in which all and rests.
If the disk is the bottleneck for replication, and use something more powerful is not possible, you need to reduce disk load.
First, you can adjust the amount of information that the master writes to binary log, and thus sent over the network and writes/reads on the slave. Settings that are worth a look:
binlog_rows_query_log_events, binlog_row_image.Secondly, you can disable the binary log on the slave. It is needed only in the case if a slave is itself a master (multi-master topology, or as an intermediate master in a cascaded replication). Some who have binary logging enabled in order to accelerate the switching of the slave mode to the master in case of failover. But if disk performance problems, it can and should be disabled.
Thirdly, it is possible to relax the durability settings for a slave. Slave by definition is irrelevant (due to asynchrony) and not the only copy of the data, and in case of his fall it is possible to recreate any backup, either from the master or from another slave. So there is no point to keep strict settings durability, keywords:
sync_binlog, innodb_flush_log_at_trx_commit, innodb_doublewrite.Finally, the General configuration of InnoDB intensive record has not been canceled. Keywords:
innodb_max_dirty_pages_pct, innodb_stats_persistent, innodb_adaptive_flushing, innodb_flush_neighbors, innodb_write_io_threads , innodb_io_capacity, innodb_purge_threads, innodb_log_file_size, innodb_log_buffer_size.If nothing helps, you can look at the engine, TokuDB, which is first optimized for intensive records, particularly if data will not fit in memory, and secondly provides the possibility of organizing read-free replication. It may solve the problem in IO-bound and CPU-bound workloads.
the
If you hit a CPU
During intensive recording on the master and no other bottlenecks on the slave (network, disk), you can rest against the processor. Here comes to the aid of parallel replication, it is also multi-threaded slave (MTS).
5.6 MTS was done in a very limited way: in parallel run only the updates in two different databases (schemas in PostgreSQL terminology). But surely there exists a non-empty set of users and that is enough (Hello, hosters!).
5.7 MTS was extended to parallel execution of arbitrary updates. In the early release candidates versions 5.7 parallelism limited to the number of simultaneously recorded transactions within the group commit. This reduced parallelism, especially for systems with fast drives, which most likely led to the lack of effective results from those who these early versions were tested. This is quite normal, to ensure they are an early version that interested users can test and criticize. But not all users think to make this report with the conclusion "PostgreSQL will conquer the world".
However, here are the results of the same sysbench test, which used to report to Oleg, but on the GA release 5.7. What we see in the dry rest:
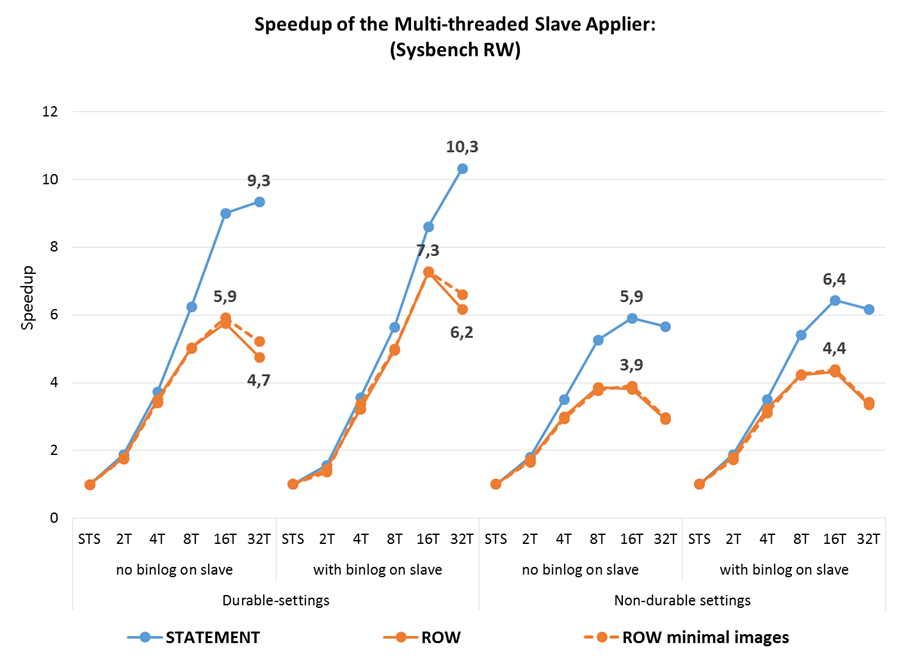
the
-
the
- MTS on the slave up to 10 times performance increase compared to single-threaded replication the
- using
slave_parallel_workers=4already leads to an increase in the capacity of a slave in more than 3.5 times
the - performance row-based replication is almost always higher than statement-based. But MTS has a greater effect on statement-based, which to some extent both from the point of view of performance on OLTP loads.
Another important conclusion from testing Booking.com the smaller the transaction size, the more parallelism can be achieved. Before the advent of group commit in 5.6, the developers tried to make the transaction as much as possible, often without the need from the point of view of applications. Starting with 5.6, this is not necessary, and for parallel replication in 5.7 it is better to revise transactions to be broken into smaller ones where possible.
In addition, you can adjust the parameters
binlog_group_commit_sync_delay and binlog_group_commit_sync_no_delay_count on the master, which can lead to more parallelism on the slave even in case of long transactions.On this topic, replication in MySQL and popular report I think closed, go to PostgreSQL.
the
Physical replication in PostgreSQL
In addition to all the advantages and disadvantages of physical replication listed earlier, the implementation in PostgreSQL has another major drawback: replication compatibility is not guaranteed between major releases of PostgreSQL, because it does not guarantee the compatibility of WAL. It really is a serious disadvantage for loaded projects and large clusters: required to stop the wizard upgrade, then full regeneration of the slaves. For comparison: problem with replication from old versions to new in MySQL happen but correct them and in most cases it works, from the compatibility of no one refuses. To be used when upgrading large clusters — plus "flawed" logic of replication.
PostgreSQL provides the ability to read data from the slave (the so-called Hot Standby), but this all is not so simple as when logical replication. Of the documentation on Hot Standby found out that:
the
-
the
SELECT ... FOR SHARE | UPDATEare not supported because this requires modification of data files
the - 2PC commands are not supported for the same reasons the
- an explicit "read write" state of a transaction (
BEGIN READ WRITE, etc.), LISTEN, UNLISTEN, NOTIFY, update sequence are not supported. That in General is understandable, But it means that some apps need to be rewritten when migrating to the Hot Standby, even if there is no data they do not modify
the - Even read-only queries can cause conflicts with DDL and vacuum operations on the master (hi "aggressive" settings vacuum!) In this case, the queries can either delay replication or be forcibly interrupted and there are configuration options that control this behavior the
- slave can be configured to provide feedback to the master (option
hot_standby_feedback). Which is good, but interesting overhead of this mechanism in the loaded systems.
In addition, I found a wonderful warning in the documentation:
the
"Operations on hash indexes are not presently WAL-logged, so replay will not update these indexes" — uh, how is this possible? And physical backups that?
There are some features failover that the MySQL user can seem strange, for example the impossibility of returning to the old master after failover without a rebase. Quoting the documentation:
Once failover to the standby occurs, there is only a single server in operation. This is known as a degenerate state. The former standby is now the primary, but the former primary is down and might stay down. To return to normal operation, a standby server must be recreated, either on the former primary system when it comes up, or on a third, possibly new, system.
There is one particular feature of physical replication in PostgreSQL. As I wrote above, the overhead traffic to physical replication is generally higher than in the logical. But in the case of PostgeSQL at WAL written (and hence transferred over the network) the full images are updated after a checkpoint s of pages (
full_page_writes). I can easily imagine a load where such behavior could be a disaster. Here surely few people will rush to explain to me the meaning of full_page_writes. I know, just in InnoDB is implemented differently, not using the transaction log.updated 28.09.2016: the same problems with replication, but English words in the article Uber engineers about the causes of the transition from PostgreSQL to MySQL: eng.uber.com/mysql-migration
updated 30.10.2017: a Curious problem, which arose precisely from the fact that replication is in PostgreSQL, physical: thebuild.com/blog/2017/10/27/streaming-replication-stopped-one-more-thing-to-check
The rest of physical replication in PostgreSQL probably really reliable and simple to set up a mechanism for those who physical replication in General works.
But the PostgreSQL user too, and nothing human is alien to them. Someone sometimes want multi-source. And someone multi-master replication or partial love. Perhaps that is why there is...
the
Logical replication in PostgreSQL
I tried to understand the state of the logical replication for PostgreSQL, and depressed. Built-in no, there are plenty of third-party solutions (who said "confusion"?): Slony-I (by the way, where Slony-II?), Bucardo, Londiste, BDR, pgpool 1/2, Logical Decoding, and that's not counting the dead, or proprietary projects.
Everybody's got their problems — some look familiar (for they are often criticized replication in MySQL), some look strange for a MySQL user. Some total trouble with replication DDL that is not supported even in Logical Decoding (wonder why?).
BDR requires a patched version of PostgreSQL (who say "forks"?).
I have some doubts about the performance. I'm sure someone in the comments will begin to explain that replication triggers and scripts in Perl/Python is working quickly, but I'll believe it when I see it comparative load tests with MySQL on the same hardware.
Logical Decoding looks interesting. But:
-
the
- Is not replication as such, but the designer/framework/API for building third-party solutions for logical replication the
- Using Logical Decoding requires recording additional information in the WAL (you want to set
wal_level=logical). Hey critics of the binary log in MySQL! - From reading the documentation I was under the impression that it is an analogue of row-based replication in MySQL, just with lots of restrictions: no parallelism in principle, no GTID (as do the cloning of a slave and failover/switchover in complex topologies?), cascading replication is not supported. the
- If I understand correctly these slides SQL interface in Logical Decoding uses a Poll model for change propagation, and the Protocol for replication uses a Push model. If so, what happens when the temporary loss of the slave from replication in the Push model, for example due to network problems? the
- There is support for synchronous replication, which is good. How about semisynchronous replication, which is more relevant in highly loaded clusters? the
- you Can choose the redundancy of information with the option
REPLICA IDENTITYfor the table. This is an analogue variablebinlog_row_imagein MySQL. But in the MySQL variable is dynamic, it can be set separately for a session or even for each individual request. Is it possible in PostgreSQL?
the - in Short, where can I see the report, "Asynchronous logical replication in PostgreSQL without censorship"?. I would love honored and looked up.
Some of the third-party solutions already moved to the Logical Decoding and which may not. the
As I said, I make no claims in terms of knowledge of PostgreSQL. If any of this is incorrect, or inaccurate — let me know in the comments and I'll correct it. It would be interesting to get answers to questions that I had along the way.
But my impression in General: logical replication in PostgreSQL is in the early stages of development. Boolean in MySQL replication has a long history, all of its pros, cons and pitfalls are well known, studied, discussed and shown in the miscellaneous reports. In addition, it has changed dramatically in recent years.
the
Conclusion
Because this publication contains some criticism of PostgreSQL, I predict another explosion of reviews in the style: "and here we are with a buddy the two of us worked on the muscle and it was bad, and now working on the elephant and life is normal". I believe. No, seriously. But I do not urge to go somewhere or anything at all to change.
The article pursues two goals:
1) the answer is not quite correct criticism and MySQL
2) attempt to systematize the many differences between MySQL and PostgreSQL. Such comparisons require great work, but this is what I often expect in the comments.
In next post I am going to continue the comparison, this time in the light of performance.



Комментарии
Отправить комментарий