As I was writing my "Bicycle" to dotirovanie tables in Oracle and Postgre
Greetings, Habr!
In this article I will tell about how we struggled with the problem of rapid growth the size of the tables in the database on busy EMS system. The highlight adds that the problem has been solved for two databases: Oracle and Postgre. Interested please under cat.
So, there is a certain EMS system that receives and processes messages from network elements. A record of each message is logged in the database table. According to customer requirements the number of incoming messages (and therefore number of records in the table) is an average of 100 per second, while the peak load may increase to 1500.
It is easy to calculate that a day on average, more than 8 million records in the table. The problem appeared when it turned out that when the data volumes of more than 20 million rows some queries of the system begin to slow down and to go beyond the work time requested by the customer.
Thus, I had to figure out what to do with the data, so no information is lost and the queries worked quickly. While initially the system worked on Postgre, but soon planned the transition to Oracle and wish the transition was a minimum of problems with the transfer functionality.
The option of using partitioning dropped immediately, because it was known that Oracle Partitioning is not exactly will be included in the license, and to alter from one to another parterning don't really like, so began to think over the implementation of some of his Bicycle.
Facilitated the task that logs older than a couple of days do not need to display in the system, because to investigate the vast majority of problems should be enough of messages from two days ago. But keep them "just in case" of need. And then the idea was born to implement procedures for periodic "dotirovanie" the data in the tables, i.e. transfer them from the tables to display some of the historical table.
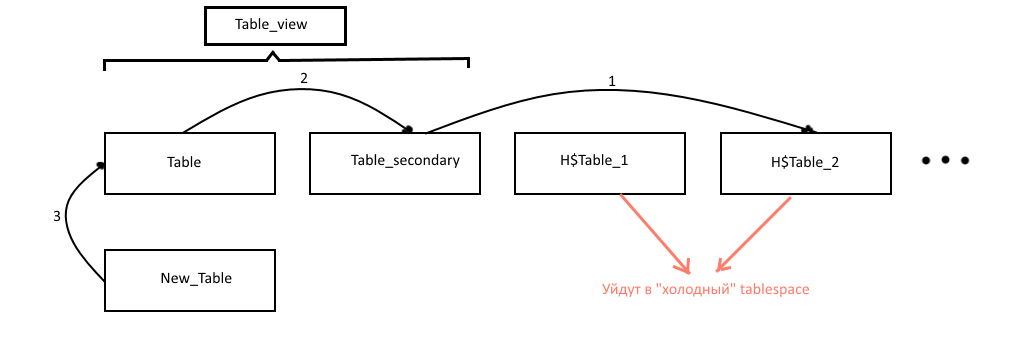
It was decided to keep 2 tables with the most relevant data to display (let's call them table — basic and table_secondary is optional). These two hung table view table_view from which were taken the data to display: it's after the moment of the transfer data in the UI drastically missing all records. Older records are transferred to the historical table with the names of the type H$table_NUM, where NUM is the number of historical table (the data older than the number above). Historical table, so as not to clog the main tablespace, also occasionally dragged into the "cold" tablespace, tables which can be stored on slower disks. Surgery is generally heavy, so is rarely a separate procedure. In addition, the procedure removes from the "cold" too old tablespace of the table.
About how exactly you migrate the data: due to the large number of indexes on the tables transfer directly to records using insert'and worked slowly, so we chose the approach with renaming of tables and recreating indexes and triggers.
Schematically, the work procedures presented in the figure below:
So, the algorithm works out roughly like this (the algorithm and example code, cite procedures for oracle, postgre will be able to view on github):
Procedure rotate_table(primary_table_name). Runs, say, every hour.
Procedure move_history_logs_to_cold_ts(primary_table_name). Executed, e.g., once a day.
Startup procedures are on schedule was done with Quartz Sheduler in case of Postgre, and using Oracle Scheduler in Oracle, scripts for configuration, which is also in the source code.
Full source code of procedures and scripts for configuration scheduler can be viewed at GitHub.
Thank you for your attention!
Article based on information from habrahabr.ru
In this article I will tell about how we struggled with the problem of rapid growth the size of the tables in the database on busy EMS system. The highlight adds that the problem has been solved for two databases: Oracle and Postgre. Interested please under cat.
Initial conditions
So, there is a certain EMS system that receives and processes messages from network elements. A record of each message is logged in the database table. According to customer requirements the number of incoming messages (and therefore number of records in the table) is an average of 100 per second, while the peak load may increase to 1500.
It is easy to calculate that a day on average, more than 8 million records in the table. The problem appeared when it turned out that when the data volumes of more than 20 million rows some queries of the system begin to slow down and to go beyond the work time requested by the customer.
Task
Thus, I had to figure out what to do with the data, so no information is lost and the queries worked quickly. While initially the system worked on Postgre, but soon planned the transition to Oracle and wish the transition was a minimum of problems with the transfer functionality.
The option of using partitioning dropped immediately, because it was known that Oracle Partitioning is not exactly will be included in the license, and to alter from one to another parterning don't really like, so began to think over the implementation of some of his Bicycle.
Facilitated the task that logs older than a couple of days do not need to display in the system, because to investigate the vast majority of problems should be enough of messages from two days ago. But keep them "just in case" of need. And then the idea was born to implement procedures for periodic "dotirovanie" the data in the tables, i.e. transfer them from the tables to display some of the historical table.
Solution implementation
It was decided to keep 2 tables with the most relevant data to display (let's call them table — basic and table_secondary is optional). These two hung table view table_view from which were taken the data to display: it's after the moment of the transfer data in the UI drastically missing all records. Older records are transferred to the historical table with the names of the type H$table_NUM, where NUM is the number of historical table (the data older than the number above). Historical table, so as not to clog the main tablespace, also occasionally dragged into the "cold" tablespace, tables which can be stored on slower disks. Surgery is generally heavy, so is rarely a separate procedure. In addition, the procedure removes from the "cold" too old tablespace of the table.
About how exactly you migrate the data: due to the large number of indexes on the tables transfer directly to records using insert'and worked slowly, so we chose the approach with renaming of tables and recreating indexes and triggers.
Schematically, the work procedures presented in the figure below:
So, the algorithm works out roughly like this (the algorithm and example code, cite procedures for oracle, postgre will be able to view on github):
Procedure rotate_table(primary_table_name). Runs, say, every hour.
-
the
- Check that the number of rows in the main table has exceeded a certain limit; the
- Check that there is a "cold" tablespace:
theSELECT COUNT(*) INTO if_cold_ts_exists FROM USER_TABLESPACES WHERE tablespace_name = 'EMS_HISTORICAL_DATA';
the - Create an empty auxiliary table new_table based on the current main table. To do this in postgre has user-friendly functionality CREATE TABLE... (LIKE... INCLUDING ALL), Oracle also had to write its counterpart — the procedure create_tbl_like_including_all(primary_table_name, new_table_name, new_idx_trg_postfix, new_idx_trg_prefix), which creates a similar empty table:
theSELECT replace(dbms_metadata.get_ddl('TABLE', primary_table_name), primary_table_name, new_table_name) INTO ddl_query FROM dual; ddl_query := substr(ddl_query, 1, length(ddl_query) - 1); EXECUTE IMMEDIATE ddl_query;
And triggers, and indexes to it:
theFOR idx IN (SELECT idxs.index_name FROM user_indexes idxs WHERE idxs.table_name = primary_table_name) LOOP ddl_query := REPLACE( REPLACE(dbms_metadata.get_ddl('INDEX', idx.index_name), primary_table_name, new_table_name), idx.index_name, new_idx_trg_prefix || idx.index_name || new_idx_trg_postfix); ddl_query := substr(ddl_query, 1, length(ddl_query) - 1); EXECUTE IMMEDIATE ddl_query; END LOOP;
the - Rename table
theEXECUTE IMMEDIATE 'alter table' || secondary_table_name || 'rename to' || history_table_name; EXECUTE IMMEDIATE 'alter table' || primary_table_name || 'rename to' || secondary_table_name; EXECUTE IMMEDIATE 'alter table' || new_table_name || 'rename to' || primary_table_name;
the - Rename the triggers and indexes on them; the
- If cold tablespace does not exist, we believe that historical data store is not necessary, and delete the relevant table:
theEXECUTE IMMEDIATE 'drop table' || history_table_name || 'cascade CONSTRAINTS';
the - Perform rebild views (oracle only):
theEXECUTE IMMEDIATE 'select * from' || view_name || 'where 1=0';
Procedure move_history_logs_to_cold_ts(primary_table_name). Executed, e.g., once a day.
-
the
- If the "cold" tablespace exists, looking for all the historical tables that are not in the tablespace:
theEXECUTE IMMEDIATE 'select table_name from user_tables where table_name like "' || history_table_pattern || "' and (tablespace_name != "EMS_HISTORICAL_DATA" or tablespace_name is null)' BULK COLLECT INTO history_tables;
the - Roaming each table in the "cold" tablespace:
theEXECUTE IMMEDIATE 'ALTER TABLE' || history_tables(i) || 'MOVE TABLESPACE ems_historical_data';
the - moved to Deleted tables, triggers and indexes; the
- Performed a delete too old tables from "cold" tablespace.
Startup procedures are on schedule was done with Quartz Sheduler in case of Postgre, and using Oracle Scheduler in Oracle, scripts for configuration, which is also in the source code.
Opinion
Full source code of procedures and scripts for configuration scheduler can be viewed at GitHub.
Thank you for your attention!



Комментарии
Отправить комментарий